Pracowałeś już z chmurą przy projekcie hurtowni danych albo data lake?
Masz już zapewne wyrobione zdanie: Co Ci się podoba, a co jest chwytem marketingowym, co wymaga dopracowania, gdzie czekasz na kolejną wersję, gdzie przydałoby się lepsze API zamiast interfejsu graficznego albo odwrotnie, bardziej wolałbyś interfejs graficzny zamiast pisania kodu.
Zrozumienie chmury to nie jest proces do ogarnięcia w czasie przerwy na kawę.
Ale jeżeli masz tylko tyle czasu, wtedy należy mieć nadzieję, że masz bogatego klienta.
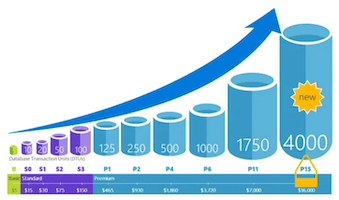
Dla bogatego klienta, przesuwasz suwak maksymalnie w prawo i już nigdy nie martwisz się o wydajność. Tacy klienci, to niestety miejska legenda.
Większość klientów patrzy uważnie, ile chmura kosztuje i czy to się opłaca.
Jeżeli szukasz argumentów, jak rozmawiać o chmurze, zapraszam.
Dzisiaj o tej jasnej stronie chmury, na przykładzie Azure.
Read More