Problem:
Potrzebujesz zrobić CDC w spark. Sprawdzić jakie wiersze się zmieniły i tylko je zaktualizować. Nie chcemy aktualizować wszystkiego bo to jest nie efektywe. Ładowanie całościowe też nie wchodzi w grę, zbiór danych jest zbyt duży.
Decyzja zapadła: będziemy liczyć sumę kontrolną (checksum) na wszystkich kolumnach w źródle i tabeli docelowej.
Jak policzyć tą sumę efektywnie? Jakiej funkcji do liczenia sumy kontrolnej użyć md5 czy xxhash64? Jakie pułapki czekają nas po drodze? Które rozwiązanie będzie szybsze?
Rozwiązanie:
Zdecydowanie szybsze będzie użycie xxhash64. Nie jest to funkcja kryptograficzna i z tego wynika jej prędkość. Ma ona jednak kilka właściwości, które mogą wygenerować problemy w kodzie i o tych problemach będzie w dzisiejszym wpisie.
Przykładowe dane
Wyobraź sobie, że masz takie, musimy przyznać, dość złośliwe dane w tabeli, które pomogą nam zobrazować problemy z funkcją xxhash:
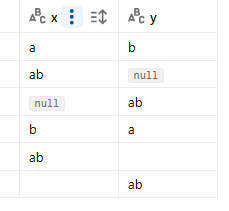
Zastosowanie xxhash( * ) sprawi, że dostaniemy taką samą checksumę dla wierszy 2 i 3, to nie jest poprawny kod.
with table1 as (
select 'a' as x, 'b' as y union all
select 'ab' as x, null as y union all
select null as x, 'ab' as y union all
select 'b' as x, 'a' as y union all
select 'ab' as x, '' as y union all
select '' as x, 'ab' as y
)
select
x, y
, xxhash64(*) as xxhash_star
from table1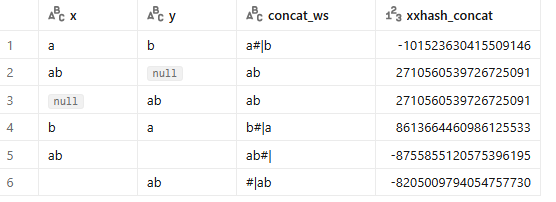
concat_ws
Spróbujmy z concat_ws
select
x, y
, concat_ws('#|', x , y) as concat_ws
, xxhash64(concat_ws('#|', x , y)) as xxhash_concat
from table1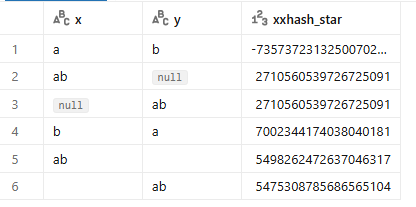
To też nie jest rozwiązanie. Wiersz 2 i trzeci nadal mają takie same checksumy.
Concat i coalsesce
select
x, y
, concat(coalesce(x,'xxx') , '#|', coalesce(y,'xxx')) as concat_coalesce
, xxhash64(concat(coalesce(x,'xxx') , '#|', coalesce(y,'xxx'))) as xxhash_concat_coalesce
from table1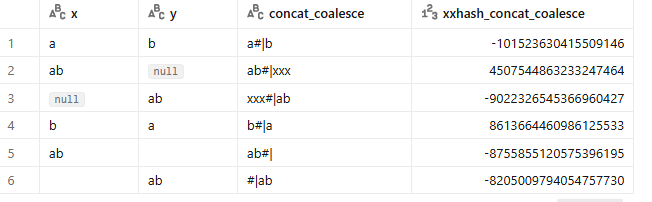
Wreszcie checksumy są różne. Wreszcie wartości nie są identyczne dla wierszy 2 i 3.
To jest jeden z dłuższych zapisów ale pozwala odpowiednio zamienić null'e na wartości. Gdy masz wiele kolumn w tabeli taka sytuacja, gdy dostaniesz taką samą checksumę dla różnych wierszy jest mało prawdopodobne. Gdy jeszcze, żeby Twój kod był bullet proof to wiesz co robić. Użyj concat i coalesce zamiast rozwiązania na leniucha, którym jest użycie gwiazdki xxhash( * ).
Podsumowanie
W 80% wypadków użycie xxhash(*) jest w zupełności wystarczające. Niestety może generować duplikaty dla wierszy, które nie są takie same.
Użycie xxhash z concat i coalesce, minimalizuje szansę na pojawienie się duplikatów w chechsumie, jest też rozwiązaniem klasy enterprise, więc polecam do zastosowania w swojej organizacji.
xxhash64(concat(coalesce(x,'xxx') , '#|', coalesce(y,'xxx'))) Pamiętasz jeszcze argument od którego zaczęliśmy na początku: xxhash jest też szybsze niż md5, dlatego w większości wypadków będzie idealnym rozwiązaniem.