Problem:
SQL jest prosty. Funkcje okienkowe są proste, intuicyjne i przychodzi bez komplikacji. Natomiast w Spark? Jak wytłumaczyć koledze w zespole w jaki sposób tworzyć funkcję okienkowe w Spark? Od czego zacząć? Jakie są problemy i wyzwania w tworzeniu funkcji okienkowych? Jakie są różnic w porównaniu z SQL? Co jest łatwiejsze w utrzymaniu?
Rozwiązanie:
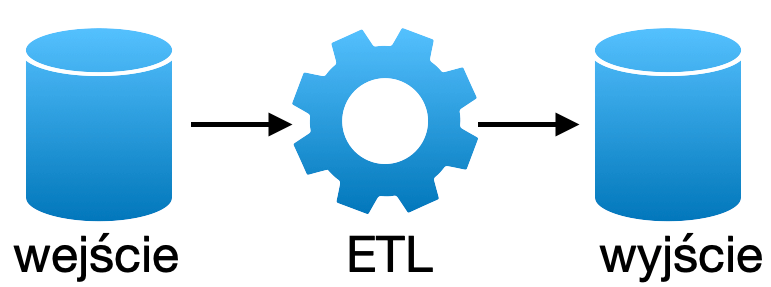
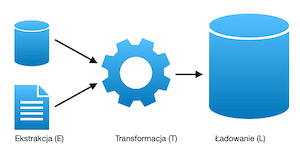
Na szybko można odpowiedzieć w ten sposób, że funkcja okienkowa tworzona jest w oderwaniu od data setu ale aplikowania na jego podzbiorze. Na przykład definicja wygląda w ten sposób:
user_window = Window.partitionBy(„user_id”).orderBy(„event_time”)
Jak to rozumieć? Dla każdego użytkownika okienko będzie posortowane po even_time i najstarsze dane będą pojawiały się na jako pierwsze a najświeższe dane wylądują w tym zbiorze danych jako ostatnie.
Potem wystarczy już tylko użyć funkcji okienkowej.
Ale zacznijmy po kolei i na przykładzie.
Read More