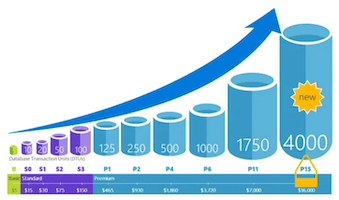
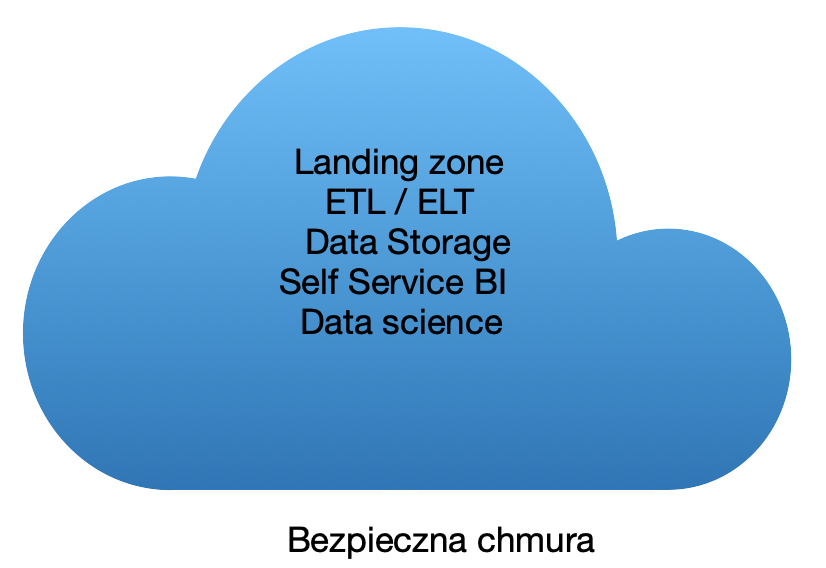
Problem:
Wysyłasz dane z on prem na Azure Storage Account. Została podjęta decyzja, że użyjesz do tego Pythona i bibliotek azure.storage. Przeglądasz dokumentacje i zastanawiasz się, którą metodę wysyłania danych do Azure wybrać? Czy lepiej wybrać append_date czy upload_data? Czy te metody mają jakieś ograniczenia? Która będzie szybsza?
Rozwiązanie:
Użycie upload_data jest zazwyczaj szybsze, natomiast ma pewne ograniczenie. Wysyłając duże pliki możesz dostać Timeout. Ale wysyłanie danych tą metodą jest zdecydowanie szybsze. Możesz pokusić się o rozwiązanie, które próbuje zrobić upload_data a dopiero potem robi append, jeżeli upload się nie powiódł.
Ale może zacznijmy po początku.
Read More