Problem:
Projekt w którym uczestniczę ma dwie gałęzie. Jedna odpowiada za data engineering, druga za data science. Ta druga część zespołu do zbudowania modelu wnioskującego potrzebuje tylko przyrostu danych. Nie potrzebują tych danych, które się nie zmieniły. Interesują ich tylko zmieniające się dane.
Inżynierowie danych są częścią zupełnie innego obozu. Zależy im na dostarczaniu zawsze wszystkich danych. Według nich tak jest szybciej, spójniej, nie trzeba wykrywać co zostało usunięte lub zmienione. Łatwiej modyfikować layout danych w tym schemacie: dodawać lub usuwać kolumny, zmieniać typy danych.
Jak pogodzić te dwa światy?
Rozwiązanie:
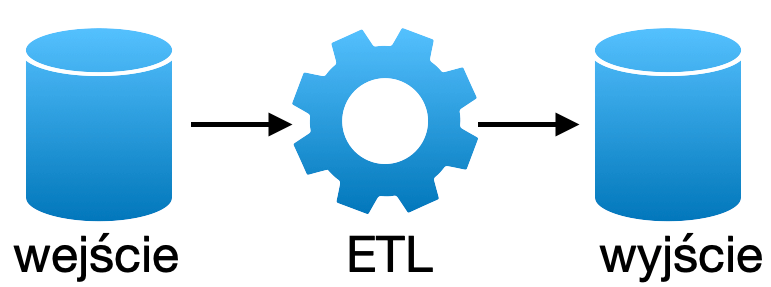
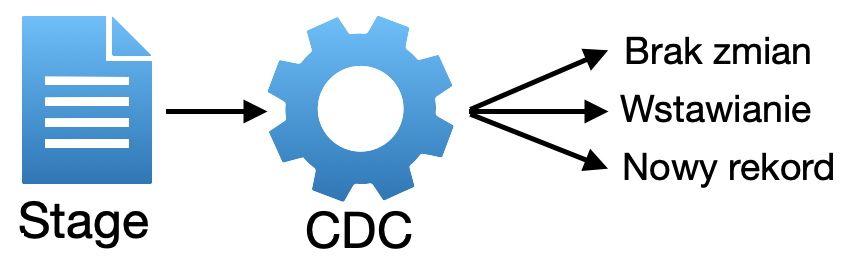
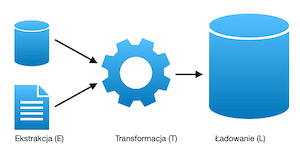
Ładowanie całościowe jest mniej problematyczne ale trzeba zadbać o jakość danych (data quality). To ważny punkt do zaadresowania z data inżynierami. Przy okazji jak zrobili już całościowy load do warstwy brązowej (bronze). Niech przygotują widoki, które będą pokazywała deltę czyli tylko to co się zmieniło. Żeby ułatwić liczenie delty każdy wiersz wystawiony do warstwy bronze przez źródło będzie posiadał własny podpis (hash, md5, xxhash64)
Read More